ГигаЧат выучил 30 языков народов России и прокачал память
Разработчики обновили ИИ-помощник ГигаЧат, — теперь базовая модель понимает сложные запросы и генерирует тексты на более чем 30 языках народов России и стран СНГ. Кроме того, в новой версии флагманской модели алгоритмы научились запоминать контекст из прошлых бесед, что выводит персонализацию взаимодействия на новый уровень.

ГигаЧат ответит на любом языке
Отечественная нейросеть получила точечную доработку для поддержки татарского, башкирского, чувашского, удмуртского, якутского, бурятского, чеченского, осетинского, карачаево-балкарского и ряда других языков. С их учетом общее количество языков, доступных ГигаЧату, превысило 40. Переключение происходит бесшовно: вам достаточно обратиться к ИИ на нужном языке, и алгоритм автоматически подстроит формат ответов.
Аналитики выделяют несколько факторов, почему важна локализация крупных языковых моделей:
- Решение бытовых задач: возможность поручить ИИ разбор сложного юридического договора, помощь ребенку с домашним заданием или поиск инструкций к технике на том языке, на котором пользователь думает.
- Доступность цифровой среды: более простое взаимодействие с государственными сервисами и интернетом в целом для пожилых людей.
- Сохранение наследия: оцифровка исторической памяти и поддержка локальных культур за счет интеграции национальных языков в сферу ИИ-сервисов, образования и туризма.
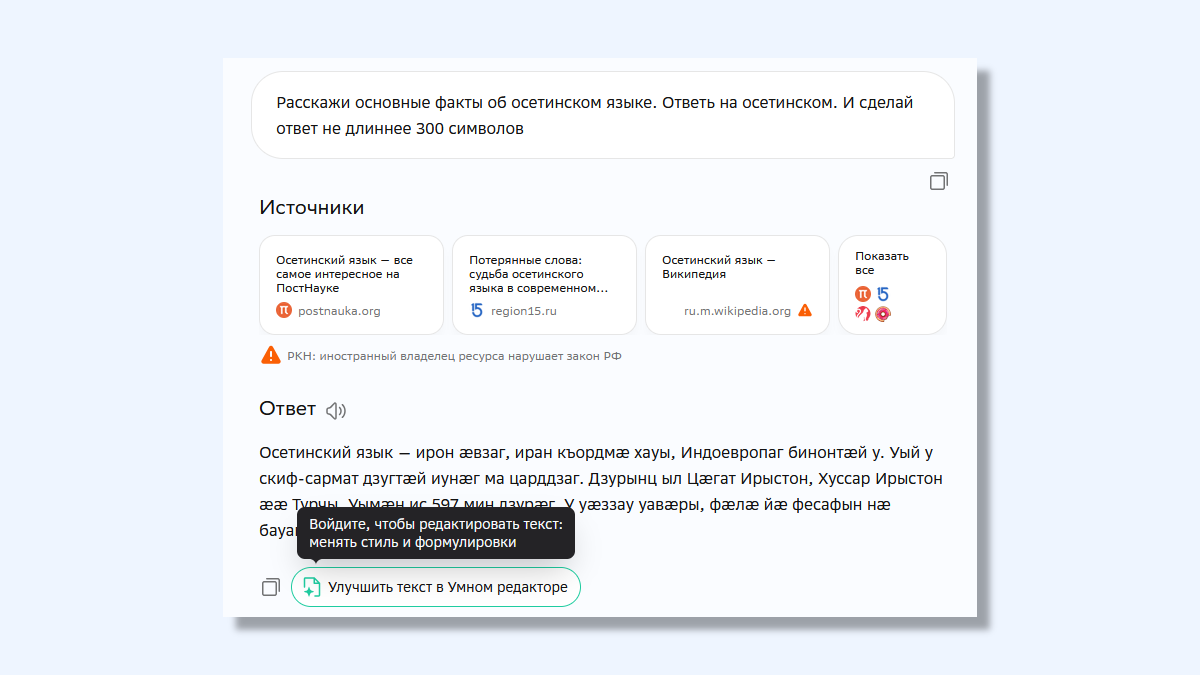
Пример ответа от ГигаЧат на осетинском языке
Также планы по развитию ГигаЧата прокомментировал Антон Фролов, старший вице-президент, руководитель блока «Развитие генеративного ИИ» Сбера:
Мы хотим сделать ГигаЧат по-настоящему массовым продуктом — таким, которым сможет воспользоваться каждый житель страны. В России используют более 270 языков и диалектов, и мы ставим перед собой задачу, чтобы как можно больше жителей могли общаться с нашим ИИ-помощником на родном языке. Когда человек может объяснить задачу своими словами, на языке, на котором он думает и чувствует, ИИ-помощник становится по-настоящему полезным инструментом в обычной жизни — будь то помощь ребёнку с учёбой, разбор юридического договора или инструкция по настройке новой техники.
Технологические трудности: как обучали модель
При обучении модели возникла серьёзная проблема — многие национальные языки слабо представлены в цифровой среде. Разработчикам банально не хватало объема данных.
Чтобы компенсировать дефицит, Сбер привлек к сбору данных множество партнеров: ФГБУ «Дом народов России», энциклопедию «Рувики», а также региональные институты, библиотеки и академии наук. Обучающий набор по каждому языку варьировался от сотен тысяч до миллионов документов. В базу массивов вошли архивы, учебные материалы, новостные публикации и живая разговорная речь.
Дополнительно к процессу подключили носителей языка. Они выступали в роли экспертов по верификации: проверяли грамматику, стилистику и естественность ответов. Сообщается, что команда оптимизировала сами алгоритмы обработки национальных языков, что позволило добиться высокой точности генерации даже при компактных датасетах.
Флагманская модель: долгосрочная память и удвоенная скорость
Параллельно с языковым расширением разработчики представили новую версию ГигаЧат Ультра. Ключевым нововведением стала функция долгосрочной памяти. В отличие от контекстной памяти, которая полностью сбрасывалась при завершении диалога, обновленный ИИ способен сохранять бэкграунд профиля:
- Учет предпочтений: модель запоминает информацию о профессии пользователя, его увлечениях и данных о близких, используя это в последующих беседах.
- Умная фильтрация: алгоритм самостоятельно отбирает только значимые факты, чтобы не перегружать вычислительную память мелкими деталями.
- Автономный поиск: ИИ-помощник научился самостоятельно определять моменты, когда для актуального ответа необходимо выйти в интернет.
- Производительность: скорость генерации текста алгоритмом выросла в два раза.
Кроме того, генеративная модель ГигаЧат полностью разработана внутри страны — от разметки данных до финального дообучения — на собственной инфраструктуре Сбера.
Протестировать возможности нейросети, включая работу с национальными языками и новую систему памяти, можно бесплатно. Сервис доступен через веб-интерфейс, популярные мессенджеры, а также в формате мобильного приложения для Android (RuStore, AppGallery). Для активации голосового режима и включения долгосрочной памяти потребуется авторизация через Сбер ID и настройка профиля.
Подписывайтесь на «Рамблер» в Max! Так мы останемся на связи даже в нестабильные времена.